
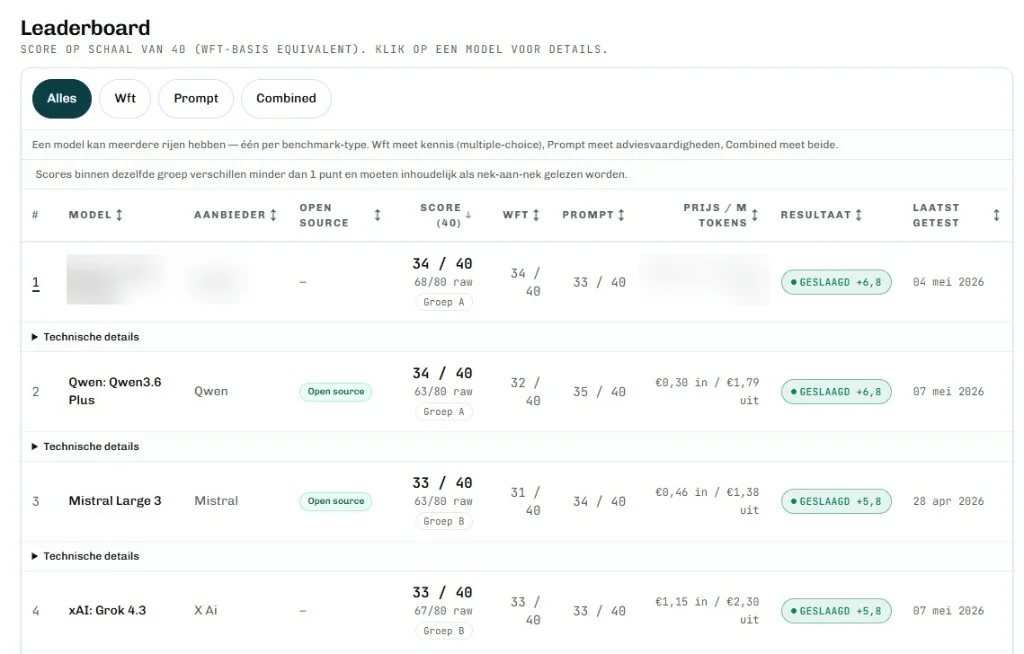
De afgelopen maanden testte ik meer dan dertien verschillende AI-modellen op verzekeringsadvies. Mistral, GPT-4.1, Claude, Gemini, Grok, DeepSeek en een rij anderen. Voor een project waarin ik beoordeel hoe goed deze systemen zijn in verzekeringsadvies. Een eenvoudige openingsvraag uit die test: wat is het wettelijk verplichte eigen risico bij de basisverzekering?
GPT-4.1 antwoordde: "Het wettelijk verplicht eigen risico in de basisverzekering is in 2024 €385 per jaar." Het bedrag klopte. Het jaartal was twee jaar oud.
Dat lijkt een detail. Het is geen detail. Het is de kern van een groter probleem dat bij twaalf van de dertien modellen terugkwam: ze citeren feiten uit hun training en gokken dat het nu nog steeds zo is. In dit geval hadden ze geluk, want het eigen risico is sinds 2016 bevroren op €385. Stel dat het in 2026 was verlaagd naar €165 — zoals het kabinet van plan was — dan had bijna elk advies pertinent fout gezeten. Eén model gaf consistent het juiste antwoord met het juiste jaartal: Gemini.
Mijn eerste reactie was dat Gemini gewoon slimmer was. Maar dat klopt niet. De andere modellen zijn ook niet dommer. Ze zijn aangesloten op een andere zoekmachine. En dat is de hele verklaring.
De kennishorizon zit niet in het model, maar in zijn zoekmachine
Een AI-model leert van een enorme berg tekst. Op een bepaald moment stopt die training. Alles wat daarna gebeurt, weet het model niet — tenzij het ergens kan zoeken. Moderne modellen doen dat: ze pakken een vraag, sturen die naar een zoekmachine, lezen de eerste resultaten en formuleren hun antwoord. Hallucinaties nemen dan sterk af. Bronvermeldingen verschijnen.
Maar er zit een addertje onder het gras. De kwaliteit van het antwoord wordt niet bepaald door hoe slim het model is. Het wordt bepaald door welke zoekmachine eraan vastzit. Als die verouderde resultaten oplevert, krijg je een verouderd antwoord. Hoe slim het model er ook bovenop zit.
Google's index is een wapen geworden
Google verwerkt nog altijd ongeveer negen op de tien zoekopdrachten ter wereld, zo blijkt uit StatCounter-data (opent in nieuw venster). Dat alleen al is een schaalvoordeel. Maar waar het echt om draait, is de index — de lijst van pagina's die Google kent en waar het uit kan putten. De index van Google is aanzienlijk groter dan die van Bing en Brave samen. Dat is een breed gedeeld uitgangspunt in de SEO-branche, al zijn exacte cijfers niet openbaar.
Wat Google daar bovenop doet is filteren. Decennia aan ervaring met spambestrijding, autoriteitsbepaling en relevantie zit in die filters. Een resultaat dat door Google wordt opgehaald is al een paar keer door een zeef geweest voor het bij jou belandt. Bij andere indexen is die zeef minder fijnmazig.
Gemini krijgt al die kracht ingebouwd. Het heet bij Google Grounding with Google Search (opent in nieuw venster) en het is geen losse plug-in maar een vast onderdeel van het systeem. Stel je een vraag over iets wat vanmiddag in het nieuws kwam, dan is het er waarschijnlijk al. Stel je een vraag over een lokaal bedrijf, dan haalt het de openingstijden uit Maps. Vraag je naar een wetenschappelijk artikel, dan zoekt het in Google Scholar.
Dat is geen marginaal voordeel. Dat is een ander gereedschap.
De anderen leven van geleende data
ChatGPT zoekt primair via Microsoft Bing — een logisch huwelijk, want OpenAI en Microsoft werken nauw samen. OpenAI gebruikt ook andere, niet-openbaar gemaakte bronnen naast Bing, maar de Bing-index vormt de ruggengraat. Voor populaire nieuwsonderwerpen werkt dat goed. Voor specifieke of niche-vragen krijg je vaker matige resultaten.
Claude, het model van Anthropic, kiest weer een andere weg. Dat zoekt via Brave Search, een onafhankelijke index. Brave heeft het voordeel dat het geen kind is van een grote techpartij. Privacy en onafhankelijkheid zijn de winst. Het nadeel is dat de index kleiner is. Voor algemene vragen prima, voor diepe of obscure onderwerpen schiet het soms tekort.
En dan zijn er modellen die geen formele licentie hebben en stiekem Google-resultaten ophalen. Dat wordt steeds riskanter. Google heeft in december 2025 een rechtszaak aangespannen tegen SerpApi, een bedrijf dat Google-resultaten doorverkocht aan AI-ontwikkelaars. Dat was geen toevallige uitspatting. Het was een signaal: de poort is dicht voor wie niet betaalt.
Voor de gebruiker betekent dit dat AI-antwoorden zonder waarschuwing slechter kunnen worden. Een scraper die geblokkeerd wordt, een index die achterloopt, een leverancier die zijn prijzen verhoogt (opent in nieuw venster). Het is allemaal de afgelopen jaren gebeurd.
Dat is geen detail. Dat is een risico.
YouTube is het stiekem belangrijkste deel
Tot zover de webindex. Maar er is nog iets wat bijna niemand benoemt. Op YouTube wordt elke dag voor honderden jaren aan video geüpload. Tutorials, persconferenties, interviews, vlogs, productdemo's, hoorcolleges. Een enorme bron van recente kennis die voor het overgrote deel nooit als tekst op een webpagina belandt.
YouTube is van Google. Gemini heeft directe toegang tot die video's en kan transcripties uitlezen, samenvatten en gebruiken om vragen te beantwoorden. Geen andere partij mag dat zomaar. Concurrenten kunnen YouTube als bron noemen. De video's diep doorzoeken zoals Gemini dat doet: dat blijft achter een muur.
Voor recente vakinformatie is dit een blinde vlek die weinig aandacht krijgt. Stel: een verzekeraar lanceert een nieuw product en de productmanager legt het uit in een webinar op YouTube. Geen enkel ander model krijgt dat in de vingers. Voor financiële markten, technische updates, wetswijzigingen die in een parlementaire uitzending zijn besproken: idem.
We meten AI-modellen bijna altijd op tekst. We vergeten dat een gigantische bron van actuele kennis tegenwoordig in beeld en geluid wordt geproduceerd — en dat de eigenaar daarvan precies één bedrijf is.
Wat dit betekende in mijn verzekeringstest
Terug naar het eigen risico. De foute antwoorden hadden allemaal dezelfde signatuur: ze refereerden aan een jaar dat voorbij is. 2024 bij GPT-4.1. 2023 bij een ander model. "Op dit moment" zonder jaartal bij een derde, alsof dat de verantwoordelijkheid wegneemt.
Wat me opviel: het foute jaartal werd elke keer met grote stelligheid gegeven. Geen enkele waarschuwing dat de informatie misschien niet meer klopte. Geen enkele suggestie om het na te checken. Vol vertrouwen baseerden ze advies op data van twee tot drie jaar oud.
In dit specifieke geval was de schade beperkt, want het bedrag is sinds 2016 bevroren. Maar in een wereld waarin het kabinet het eigen risico per 2027 zou verlagen naar €165, en waarin polisvoorwaarden, premies, dekkingen en wetgeving wel jaarlijks veranderen, is mazzel geen adviesgrondslag.
Gemini deed één ding anders. Het antwoord was: "Het verplichte eigen risico voor de basisverzekering is in 2026 vastgesteld op €385." Het juiste bedrag, het juiste jaar. Niet omdat Gemini slimmer is. Maar omdat Gemini een betere informatiestroom heeft.
Voor mij heeft dat consequenties voor hoe ik werk. Voor recente cijfers, regelgeving, productinformatie of nieuws gebruik ik Gemini als eerste check. Niet omdat het mijn favoriete model is voor schrijven of redeneren — daar vind ik Claude vaak sterker. Wel omdat het feitelijk vaker klopt. En in een adviescontext is feitelijk kloppen niet onderhandelbaar.
De moat die niemand kan inhalen
Dit alles maakt iets zichtbaar wat ik in mijn eerdere blog over data als moat al beschreef. Iedereen kan een AI-model bouwen. Niet iedereen heeft een eigen dataspoor om dat model van te voeden. En de partij die de meest complete index van het web heeft — plus alle YouTube-video's, plus Maps, plus Scholar — heeft een voorsprong die met geld of slim coderen niet te dichten is.
Concurrenten kunnen wel slimmer zoeken. ChatGPT stelt in zijn nieuwste versies extra zoekopdrachten als het denkt dat het iets mist. Claude is sterk in het diep doordenken van wat het wel vindt. Perplexity verpakt resultaten in nette samenvattingen met heldere bronvermeldingen. Het zijn echte oplossingen. Maar ze compenseren een tekort aan diepte met betere verwerking. Op feitelijke vragen waarbij recente data essentieel zijn wint de partij met de beste data, niet de slimste verwerking.
Drie dingen die ik anders ben gaan doen
1. Kies je AI op basis van de taak, niet op basis van merkvoorkeur
Voor recente feiten en lokale informatie pak ik Gemini. Voor coderen, doordenken, schrijven en het analyseren van lange documenten pak ik Claude. Voor algemene gesprekken en logica werk ik vaak met ChatGPT. Een hamer is geen schroevendraaier. Het is geen verraad om te wisselen. Het is gezond verstand.
2. Vraag altijd door op cijfers en datums
Een AI-model kan met grote zekerheid een bedrag noemen dat al twee jaar oud is. Vraag waar het cijfer vandaan komt. Vraag wanneer het is bijgewerkt. Vraag of er een recentere versie is. Een goed model laat zich niet uit het veld slaan door een check. Een slecht model bekent in de tweede ronde dat het zelf ook niet zeker is. Precies de informatie die je nodig hebt.
3. Vertrouw nooit blind op één bron, ook al is het een AI
Test dezelfde vraag bij twee of drie modellen als het er echt op aankomt. Dat duurt drie minuten extra en bespaart je een fout in je advies, je rapport of je beslissing. Bij mijn verzekeringstest gaven dertien modellen bijna net zoveel varianten op dezelfde vraag. Eén had het zonder voorbehoud goed. Als je er willekeurig één had gekozen, had je minder dan 8% kans op een antwoord dat én klopt én bij het juiste jaar hoort.
De echte AI-strijd gaat niet meer over modellen
Ik denk dat de komende jaren laten zien dat de echte AI-strijd niet meer over modellen gaat. Het gaat over wie de beste data heeft. En wie er bij kan. De modellen zelf gaan steeds dichter op elkaar zitten in wat ze kunnen. De kwaliteit van het antwoord wordt voor recente vragen bijna volledig bepaald door wat eronder ligt.
Voor recente feiten heeft Google die positie nu in handen. Met de webindex, met YouTube, met Maps, met Scholar. Een combinatie die geen concurrent op korte termijn kan bouwen. Niet omdat het technisch onmogelijk is. Wel omdat de tijd, het geld en de juridische barrières te hoog zijn.
De eigen-risico-test is één vraag uit een breder benchmarkproject waar ik nu aan werk. Dertien modellen, een rij verzekeringsvragen, gescoord op accuratesse en bruikbaarheid voor advies. De bèta draait. Binnenkort gaat het project live, inclusief de volledige ranglijst en de antwoorden per model. De nummer één hou ik tot dan voor mij.
Kijk niet alleen naar wat een AI zegt. Kijk ook naar welke zoekmachine eronder ligt. Voor recente feiten is dat het hele verhaal.
Stand van zaken — juni 2026
De kern van dit stuk is sinds mei alleen maar zwaarder gaan wegen. In de eerste vier maanden van 2026 eindigde 68% van alle Google-zoekopdrachten zonder klik (Search Engine Land, 2026 (opent in nieuw venster) (opent in nieuw venster)), en AI Overviews verschijnen inmiddels boven meer dan een vijfde van de zoekresultaten, waar ze de doorklik met bijna 60% verlagen (SQ Magazine, 2026 (opent in nieuw venster) (opent in nieuw venster)). Het antwoord komt dus steeds vaker uit de zoekmachine zelf in plaats van van de website eronder. Wat dat voor je eigen vindbaarheid betekent, schreef ik eerder in mijn stuk over AI Overview en digitale zichtbaarheid (opent in nieuw venster).
Tegelijk groeit de voorsprong van de partij met de beste data. Google meldde op zijn eigen I/O-congres in 2026 dat AI Mode de grens van een miljard maandelijkse gebruikers passeerde en dat het aantal vragen elk kwartaal ruim verdubbelt (DigitalApplied, 2026 (opent in nieuw venster) (opent in nieuw venster)). Dat is precies de informatiestroom waar dit artikel over gaat, nu op schaal. Niet omdat het model slimmer is, maar omdat de zoekindex eronder dieper en verser is.
En de rechtszaak die ik noemde, draait door. Google sleepte SerpApi in december 2025 voor de rechter omdat het zoekresultaten doorverkocht aan AI-ontwikkelaars (Search Engine Land, 2025 (opent in nieuw venster) (opent in nieuw venster)). SerpApi vroeg in februari 2026 om de zaak te seponeren, en de uitspraak op dat verzoek werd na een zitting in mei verwacht (The Register, februari 2026 (opent in nieuw venster) (opent in nieuw venster)). Hoe een rechter dit beslist, bepaalt mee of de complete index van Google straks alleen nog bereikbaar is voor wie ervoor betaalt. De poort die ik beschreef, staat nog steeds op een kier.
Bronnen
- Marktaandeel zoekmachines wereldwijd: Statcounter Search Engine Market Share (opent in nieuw venster)
- Gemini's directe integratie met Google Search: Google Cloud, Grounding with Google Search (opent in nieuw venster)
- Anthropic over web search in Claude via Brave: Anthropic documentatie (opent in nieuw venster)
- Google's juridische actie tegen scrapers: Google blog over SerpApi-rechtszaak, december 2025