
TL;DR
- Car Wash Test opgelost. Zes maanden geleden faalden topmodellen op een vraag die elk kind begrijpt — nu beantwoorden ze hem correct, met droge humor erbij.
- Tegelijk 86% hallucinaties. GPT-5.5 geeft op onbekende vragen 86% van de tijd een zelfverzekerd fout antwoord, terwijl hij het hoogste feitenscore ooit haalt.
- Wiskundige doorbraken zijn echt. GPT-5.2 bewees Erdős-probleem #397 in minuten — gecontroleerd door Fields-medaillewinnaar Terence Tao als origineel werk.
- De verstrooide professor. AI is briljant op specifieke domeinen en hulpeloos op andere — geen bug, maar de huidige architectuur.
- Stap nu op de trein. Wie nu leert hoe AI werkt, doet over twee jaar uren werk waar anderen dagen over doen.
Ik tikte laatst bij ChatGPT en Claude een vraag in die mijn dochter van zes blind beantwoordt: moet ik lopen of rijden naar de wasstraat, 50 meter verderop? Een paar maanden geleden lieten ze me nog lopen. Zonder auto.
Maar diezelfde modellen kraakten deze winter wiskundige raadsels waar knappe koppen jaren omheen liepen. Beide zijn waar. En dat is precies waar dit verhaal over gaat.
Even terug naar die wasstraat, want het is een test met een naam. "Ik wil mijn auto wassen. De wasstraat is 50 meter verderop. Moet ik lopen of rijden?" Tik die zin een paar maanden geleden in bij een willekeurige top-AI en in ongeveer drie van de tien gevallen kreeg je iets terug in de trant van: "Loop! Het is maar 50 meter, dat is sneller dan instappen. Bovendien is het beter voor het milieu en doe je nog even een korte beweging."
Lees het nog eens. Klinkt redelijk. Tot je beseft dat je auto er ook moet zijn als je hem wilt wassen. Lopend ga je daar weinig schoonmaken.
Welkom bij de Car Wash Test (opent in nieuw venster). Hét virale voorbeeld uit eind 2025 om te laten zien dat AI bij de eerste de beste lastige vraag tegen de muur knalde. Geen exotisch testje, geen filosofisch dilemma. Gewoon een vraag die elke vijfjarige snapt: een auto rijdt niet uit zichzelf naar de wasstraat.
De kritikasters duiken op zulke voorbeelden alsof het bewijs is dat AI in feite niets is en niets kan. Tegelijkertijd zie ik elke dag, in mijn eigen werk, hoe AI dingen doet die ik mensen drie jaar geleden niet had zien doen in een week. Precies die spanning wil ik hier uitpluizen.
Maar… ik heb de test zelf opnieuw gedaan
Voordat ik verder klagend over AI-blunders begin: ik heb de Car Wash Test begin mei 2026 zelf nog eens uitgevoerd, gewoon de letterlijke vraag in twee chatvensters geplakt. De screenshots hieronder komen van die test.
ChatGPT eerst.

"Rijden. Niet omdat 50 meter ver is. Wel omdat je auto anders niet gewassen wordt. Loop er alleen heen als je eerst wilt vragen of de wasstraat open is. Of als je auto al zó schoon is dat hij zelf mag thuisblijven."
Goed antwoord. Klopt logisch. En er zit zelfs een vleugje droge humor in over die schone auto die mag thuisblijven.
Vervolgens Claude.
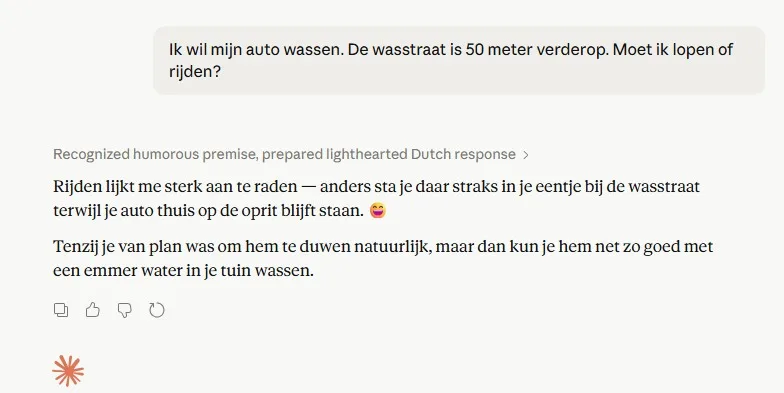
Recognized humorous premise, prepared lighthearted Dutch response.
"Rijden lijkt me sterk aan te raden, anders sta je daar straks in je eentje bij de wasstraat terwijl je auto thuis op de oprit blijft staan. 😅 Tenzij je van plan was om hem te duwen natuurlijk, maar dan kun je hem net zo goed met een emmer water in je tuin wassen."
Pak even die grijze regel: "Recognized humorous premise". Dat is geen geprogrammeerde standaardreactie. Dat is het model dat zelf herkent dat de vraag een speelse insteek heeft, en daar bewust een lichte toon op kiest. Met emoji. Met die afsluitende grap over een emmer water in de tuin.
Dit is geen Car Wash Test die AI nog faalt. Dit is een Car Wash Test die AI binnen een seconde wint. Op de gein. In het Nederlands.
Houd dit even vast. Ik kom er straks op terug.
De parade van AI-blunders (waar wel waarheid in zit)
Goed, niet alles is opgelost. De kritikasters hebben nog steeds een rijtje voorbeelden waar ze trots mee schermen. Eerlijk: het is een indrukwekkend rijtje.
Neem klok kijken. Een onderzoek gepresenteerd op de International Conference on Learning Representations (opent in nieuw venster) in 2025 testte de grote modellen (Llama, Claude, Gemini, GPT-4o) op het lezen van een analoge klok. Score: 38,7% goed. Dat is slechter dan een gemiddelde basisschoolleerling. De modellen worstelen met ruimtelijk denken: overlappende wijzers inschatten, klokontwerpen herkennen, hoeken lezen. Dingen waar wij geen seconde over nadenken.
Dan is er de hallucinatie-paradox, want die is bijna niet te geloven. Op de AA Omniscience-test van Artificial Analysis (opent in nieuw venster), die meet hoe vaak een model met overtuiging een fout antwoord geeft in plaats van eerlijk te zeggen dat het iets niet weet, komt GPT-5.5 uit op 86 procent. Claude Opus 4.7 zat op 36%, Gemini 3.1 Pro op 50%. En tegelijk haalt datzelfde GPT-5.5 de hoogste score ooit gemeten op feitelijke vragen: 57%. Hij weet dus meer. Maar als hij iets níet weet, verzint hij ook vaker iets dat plausibel klinkt (opent in nieuw venster).
En voordat je denkt dat dit een stilstaand beeld is: tegen de tijd dat je dit leest, is de wereld alweer opgeschoven. Anthropic bracht eind mei 2026 Claude Opus 4.8 uit, die Opus 4.7 na nog geen zes weken opvolgde en zijn kalibratie min of meer vasthield. Dat is precies het tempo waar dit hele stuk over gaat. De cijfers die ik hier noem, zijn een momentopname. De richting niet.
En dan is er de Car Wash Test zelf (opent in nieuw venster), lange tijd hét standaardbewijs dat AI patronen herkent maar niet nadenkt. Het model zag "korte afstand" en koppelde dat aan "lopen". Maar zoals je net hierboven zag, is dit gat in een paar maanden gedicht. Wat eind 2025 nog dé internet-meme was om AI belachelijk te maken, is in mei 2026 een binnenkomertje waar de modellen zelfs een grap over maken.
Dat laatste is precies de pointe. De voorbeelden waarmee critici willen aantonen dat AI niks waard is, zijn bijna altijd voorbeelden uit een vorige modelgeneratie. De volgende lichting heeft het opgelost voordat de blogpost over de fail goed en wel viraal was.
En toch, en toch, en toch
Hier kantelt het verhaal. Want als je alleen kijkt naar de blunders die nog wél overgebleven zijn, denk je: AI is dus hopeloos. Een veredelde tekstvoorspeller die af en toe een blunder begaat. Tot je gaat kijken naar wat er ondertussen op een heel ander niveau gebeurt.
In december 2025 stonden op de website van Erdős, de plek waar de openstaande wiskundige raadsels van Paul Erdős worden bijgehouden, honderden problemen op de status "open". Erdős liet bij zijn dood in 1996 meer dan duizend onopgeloste vraagstukken na, sommige al decennialang onaangeraakt. En sinds eind 2025 begonnen er problemen door te schuiven van "open" naar "opgelost", met AI gewoon als medeoplosser in het rijtje.
Hier moet ik meteen eerlijk zijn, want anders verkoop ik je hetzelfde rookgordijn als de hypeverkopers. In oktober 2025 claimde OpenAI dat GPT-5 tien Erdős-problemen had opgelost. Dat klopte niet. Het model had oude oplossingen teruggevonden die al ergens in de literatuur stonden, geen nieuwe wiskunde gemaakt. Thomas Bloom, die de database beheert, moest het rechtzetten en de claim werd ingetrokken (opent in nieuw venster). Veel van wat als "AI lost wiskunde op" rondgaat, is bij nader inzien een literatuurzoekopdracht met een strik eromheen.
Maar begin januari 2026 gebeurde er iets dat wél standhield. Neel Somani gaf GPT-5.2 Pro de opdracht om Erdős Probleem #397 aan te pakken, een vraagstuk uit de getaltheorie over centrale binomiaalcoëfficiënten. Het model produceerde binnen minuten een bewijs (een weerlegging, om precies te zijn: het liet zien dat de oorspronkelijke conjectuur fout was via een oneindige reeks tegenvoorbeelden). Het systeem Aristotle van Harmonic (opent in nieuw venster) zette dat om in Lean, een controletaal die wiskundigen gebruiken om bewijzen onontkoombaar correct te maken. En toen keurde Fields-medaillewinnaar Terence Tao het goed. Datzelfde GPT-5.2 kraakte in dezelfde week ook problemen #728 en #729.
En hier komt de nuance die je nergens in de hype-koppen leest, en die uitgerekend van Tao zelf komt. Hij noemt deze doorbraken het "laagsthangende fruit" (opent in nieuw venster): problemen die met standaardtechnieken op te lossen zijn, geen diepe doorbraken die de wiskunde op zijn kop zetten. Datzelfde GPT-5.2 scoort 77% op wedstrijdwiskunde, maar zakt naar 25% op open onderzoek dat echt nieuw inzicht vraagt. Het verschil met oktober is wel essentieel: dit is volgens Tao origineel werk (opent in nieuw venster), geen opgewarmde literatuur.
Dat is precies waarom het klopt. Niet omdat AI ineens slimmer is dan de slimste wiskundigen. Maar omdat een model nu, aangestuurd door een mens, in een kwartier een bewijs neerzet dat daarna door de strengste verificatie heen komt. Een jaar geleden was dat ondenkbaar.
En dan zijn er nog de andere terreinen. AI vindt slimmere algoritmes voor matrixvermenigvuldiging, een basaal rekenprobleem waar de hele AI-industrie zelf op draait. In september 2024 vond Klaus Meffert met hulp van AI een nieuwe magische zeshoek van orde 9 (opent in nieuw venster), voor het eerst sinds de orde-7-oplossing van achttien jaar daarvoor. Gewone rekenmethodes via brute kracht schoten tekort. Een aanpak waarbij AI de zware delen van de code voor zijn rekening nam, werkte wel.
En in mijn eigen werkdag? Ik heb op een vrijdagmiddag een werkende app gebouwd die schadeclaims beoordeelt op basis van een schadeformulier en foto's van de schade. Je voert de gegevens in, uploadt de foto's, en de app beoordeelt de claim. Drie jaar geleden had je daarvoor een team developers en een volledige sprint nodig. Nu kostte het een middag, zonder een regel code zelf te schrijven.
Hoe verzoen je deze twee werelden?
De verstrooide professor
Mijn favoriete vergelijking is de verstrooide professor.
Je kent het type wel. De man die op zijn tachtigste nog kwantummechanica aan de universiteit van Cambridge onderwijst, formules op een schoolbord schrijft die niemand in de zaal volledig snapt, en daarna de collegezaal verlaat met twee verschillende sokken aan en zonder zijn paraplu, in de overtuiging dat zijn auto in de andere straat staat. Terwijl hij hem op de fiets is gekomen.
Briljant op het ene domein. Pijnlijk hulpeloos op het andere. Geen tegenstelling. Hetzelfde brein.
Zo werkt AI nu ook. Modellen als GPT-5.2 kunnen op het hoogste niveau redeneren over getaltheorie en tegelijk struikelen over een vraag die je dochter van zes met haar ogen dicht beantwoordt. Dat is geen bug. Dat is hoe deze systemen op dit moment in elkaar zitten.
De diepere reden: deze modellen leren door enorme hoeveelheden tekst en patronen te verwerken. Voor wiskundige notatie, code en gestructureerd redeneren zit er in die tekst zoveel goede input dat het model effectief leert denken. Voor oorzaak en gevolg in de fysieke wereld, ruimtelijk inzicht en het simpele besef dat een auto niet uit zichzelf bij de wasstraat staat, ontbreekt die training of is hij oppervlakkig. En dus bouwt het model patronen op die voor mensen onnozel klinken, omdat ze geen contact hebben met hoe de wereld werkt.
Maar dit is precies het punt: dat verandert per maand. Je hoeft maar terug te scrollen naar die twee screenshots hierboven om dat te zien. Een test die een half jaar geleden nog dé internet-meme was om AI belachelijk te maken, wordt nu binnen een seconde correct beantwoord, met grap erbij. De modellen met een expliciete redeneer-modus scoren op al dit soort tests al beduidend beter. De volgende generatie dicht het overgebleven gat verder.
Waarom dit voor jou belangrijk is
Hier komt het deel waar ik ongezellig wil worden.
Ik zie veel mensen om me heen die naar deze AI-blunders kijken en denken: zie je wel, het is bullshit, het is een hype, het stelt niets voor. En dat is precies de verkeerde conclusie.
Want wat hier echt aan het gebeuren is: een technologie die op sommige plekken nog struikelt over een klok, kraakt in andere domeinen problemen waar wiskundigen jaren omheen liepen. Niet de allermoeilijkste, dat geef ik toe. Maar wel echte, geverifieerde wiskunde. Een jaar geleden konden die modellen nog geen behoorlijke website bouwen, nu doen ze het in twintig minuten terwijl Codex hele applicaties schrijft en je in een middag een design maakt waarvoor je vroeger naar een bureau ging. En een paar maanden geleden faalde Claude nog op de Car Wash Test. Nu maakt hij er een grapje over.
Het tempo waarin AI van "dom" naar "goed genoeg" naar "beter dan jij" gaat in nieuwe domeinen is hoger dan menselijke werkprocessen kunnen bijhouden. En dan komt mijn waarschuwing, vooral als jouw werk grotendeels achter een laptop gebeurt.
Stap nu op de trein.
Niet over een jaar. Niet als het stof is neergedaald. Nu.
Niet omdat je morgen je baan kwijt bent. Maar omdat de mensen die nu leren hoe ze AI als verlengstuk van hun denken gebruiken, over twee jaar uren werk doen waar jij dagen over doet. Dat is niet eerlijk en het is geen prettige boodschap. Maar het is wel hoe het werkt.
De verstrooide professor in je laptop is briljant in een groot deel van wat hij doet en hopeloos in een ander deel, en dat hopeloze deel wordt elke maand kleiner. Jouw taak is leren wanneer je hem wel en wanneer je hem niet moet vertrouwen. Wanneer je zelf moet doortikken. Wanneer je hem moet dwingen om eerst na te denken. Welke prompts werken en welke niet. Waar hij hallucineert en waar hij goud levert.
Dat lukt je niet door aan de zijlijn de Car Wash Test van vorig jaar mee te lachen. Dat lukt je alleen door de mouwen op te stropen, een paar uur per week te investeren en zelf met deze modellen te gaan werken.
Want ja, AI maakt nog fouten. Veel fouten. Soms domme fouten waar je op je voorhoofd voor wilt slaan.
Maar ondertussen kraakt dezelfde AI wiskundige raadsels waar mensen jaren omheen liepen, in een kwartier. En maakt hij grappen over je auto.
Beide zijn waar. En de mensen die dat begrijpen, zijn degenen die over twee jaar het verschil maken.
Bronnen
- AI's struggle to read analogue clocks may have deeper significance (opent in nieuw venster)
- GPT-5.5 hallucinates frequently (opent in nieuw venster)
- AA-Omniscience benchmark (opent in nieuw venster)
- GPT-5.2 Just Solved a 30-Year Math Problem (opent in nieuw venster)
- Drie Erdős-problemen, en de nuance van Terence Tao (opent in nieuw venster)
- Experts waarschuwen: Erdős als imperfecte AI-benchmark (opent in nieuw venster)
- OpenAI's eerdere Erdős-claim die niet klopte (opent in nieuw venster)
- New solution for magic hexagon of order 9 (opent in nieuw venster)
- The Car Wash Test (opent in nieuw venster)
- AI Car Wash Test (opent in nieuw venster)
- AI kan niet klokkijken (opent in nieuw venster)